はじめに
今回はEDINETに存在するドキュメントにどんなものがあるのかを調べていきます。なぜこんなことが必要なのかといえばEDINETから公開されているAPIからでは
- 特定の日、例えば2022年8月19日に提出された文書の一覧を取得する
- 文書IDから文書、ここではXBRLを1つダウンロードする
ことしかできないからです。
例えば「トヨタ自動車の有価証券報告書を全てダウンロードする」なんてことはできません。したがって、あらかじめ何月何日にどんなドキュメントが存在しているかがわからないと欲しいXBRLをダウンロードすることはできないわけです。
そこら辺の事情や、EDINETで管理されているドキュメント一覧のフォーマットについては以下の記事に書いてあるので読んでおいてください。
EDINETのXBRLを分析する方法 その1 - 株式銘柄紹介ブログ
本記事ではドキュメントの一覧を記録するJSONファイルをダウンロードするところまでをやっていきます。
開発環境
- windows 10 home
- python 3.7.4
- K2Editor(テキストエディタ) + コマンドプロンプト
使用したpythonの外部ライブラリ
少なくとも以下の外部ライブラリを利用しているのでインストールしていなければpipコマンドでインストールしてください。
- python-dateutil
- requests
EDINET APIを使ってJSONファイルをダウンロードする
ある日付のドキュメント一覧を取得するためにはサーバに対してHTTPリクエスト(GETメソッド)を送る必要があります。エンドポイントとかリクエストパラメータはEDINET APIの仕様書に記載があります。
EDINET APIの仕様書 p6、7、8より引用
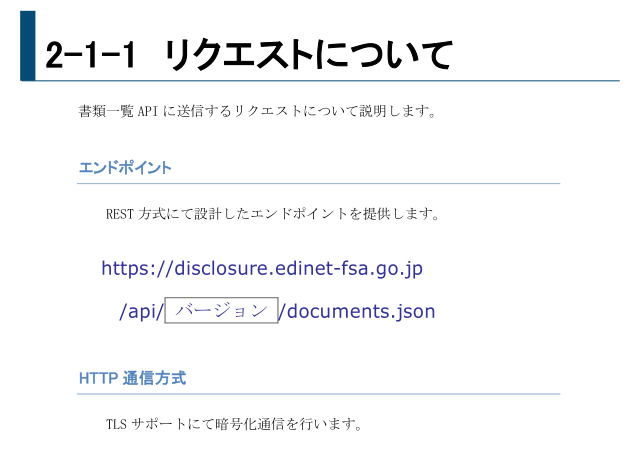
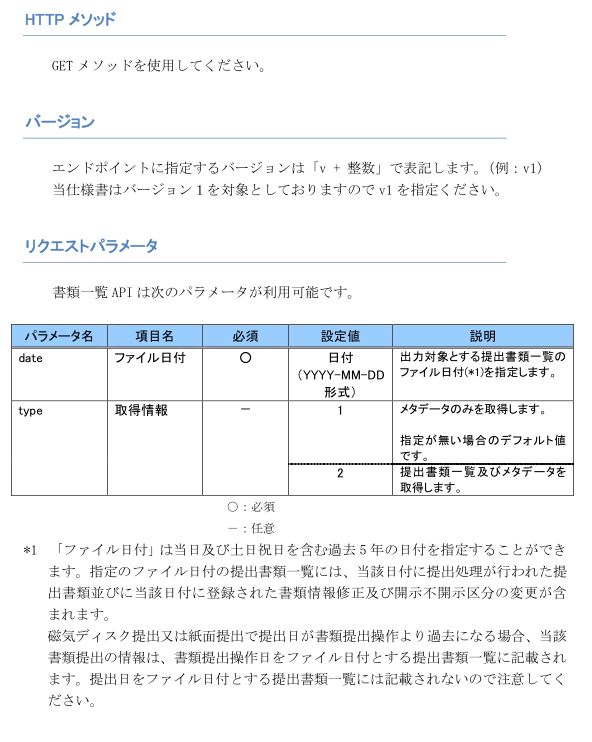

仕様書には過去5年分しか指定できないと書いてありますが、2023年から過去10年まで指定できるようになっています。
仕様に従ってリスクエストを送るコードはこんな感じになります。
import requests params = { 'type' : 2, 'date' : '2023-01-25' } res = requests.get('https://disclosure.edinet-fsa.go.jp/api/v1/documents.json', \ params=params, \ verify=False, \ timeout = 120.0) print(res.text)
実行結果
{
"metadata": {
"title": "提出された書類を把握するためのAPI",
"parameter": {
"date": "2023-01-25",
"type": "2"
},
"resultset": {
"count": 150
},
"processDateTime": "2023-01-25 13:19",
"status": "200",
"message": "OK"
},
"results": [
{
"seqNumber": 1,
"docID": "S100PZZF",
"edinetCode": "E10677",
"secCode": null,
"JCN": "9010001021473",
"filerName": "アセットマネジメントOne株式会社",
・・・
エラー処理として、サーバレスポンスのステータスコードが成功であることを確認しておきましょう。また、レスポンスヘッダ(content-type)が仕様通りであることも確認しておきたいです。サーバメンテナンス中にJSONファイルではなくhtml文書が返される場合もあるらしいので。サーバからのレスポンスはEDINET APIの仕様書に記載があるので、それを見ながらエラー処理を書いていきます。
わたしが確認できた限りですが、ステータスコード、レスポンスヘッダ(content-type)は以下のようにサーバから返されていました。
ステータスコード
- 200 正常
- 403 サーバが忙しくてアクセスを拒否
レスポンスヘッダ(content-type)
- application/json; charset=utf-8 正常
- それ以外 異常
このほかにrequests.getで例外が発生する可能性があるのですが、プログラムが止まって失敗したことがわかる分には害はないため(自分で使う分には)、例外処理はしていません。
これに従ってコードを書くと以下のようになります。
import requests import time def get_edinet_json_text(date_str) : json_text = None params = { 'type' : 2, 'date' : date_str } url = 'https://disclosure.edinet-fsa.go.jp/api/v1/documents.json' retry_count = -1 while retry_count < 10 : retry_count = retry_count + 1 time.sleep(2.0) res = requests.get(url, \ params=params, \ verify=False, \ timeout = 120.0) if res.status_code != 200 : time.sleep(60.0) continue if res.headers['content-type'] != 'application/json; charset=utf-8' : time.sleep(60.0) continue json_text = res.text break return json_text json_text = get_edinet_json_text('2023-01-25') print(json_text)
JSONファイルをチェックし保存する
といっても、JSONファイルのステータスコードが正常かを確認するだけです。基本的に正常なら200が返されるのですが、10年よりも前の日付に対してサーバにリクエストを送ると404を返します。これについて本来であれば無視すればいいのですが、10年以内であるのに404がかえってた場合を区別したいので、404が返ってきた場合はプログラムを終了するように実装します。JSONファイルの取得処理に10年よりも前の日時を与えなければよいです。
基本的に200以外が返ってきた場合はプログラムを終了するように実装します。自分が知る限り、200と404以外は見たことがないのですが、仕様上は他のコードも返す可能性があり、その際にどのように処理すべきかもよくわからないため、想定外の値が返ってきた場合はプログラムを終了し、エラーの調査が出来るようにしておきます。一番まずいのは実際にはEDINETにデータがあるのに一時的なエラーでデータが取得できておらず、抜けが発生することなのでそれを避けるように実装します。
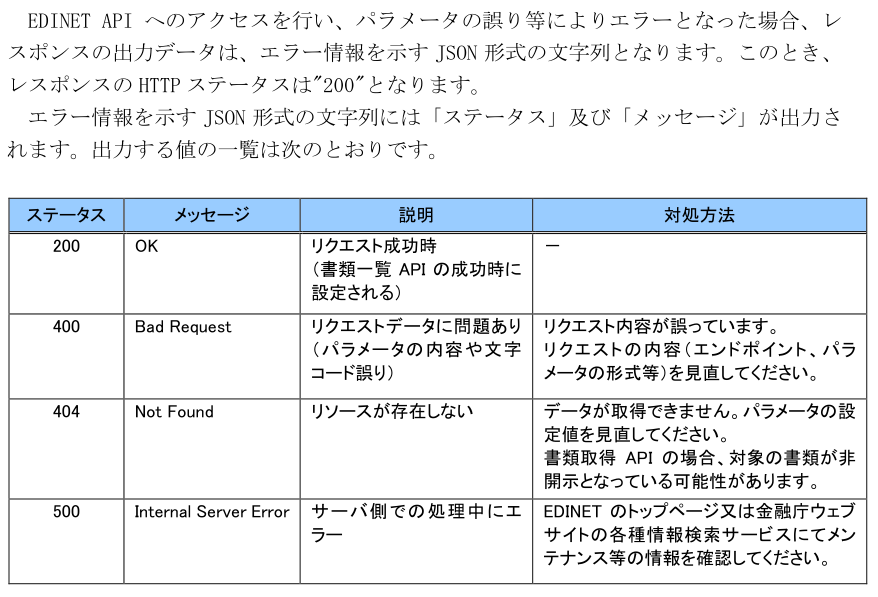
以下はJSON中のステータスコード、および、メッセージの内容一覧です。
EDINET API仕様書 p45より引用
JSONファイルは適当なディレクトリを作って保存します。
以下がコードです。
import requests import time import json import os def get_edinet_json_text(date_str) : json_text = None params = { 'type' : 2, 'date' : date_str } url = 'https://disclosure.edinet-fsa.go.jp/api/v1/documents.json' retry_count = -1 while retry_count < 10 : retry_count = retry_count + 1 print(url + '?' + t_date + 'へリクエスト送信') time.sleep(2.0) res = requests.get(url, \ params=params, \ verify=False, \ timeout = 120.0) if res.status_code != 200 : print('status_code:' + res.status_code) res.close() time.sleep(60.0) continue if res.headers['content-type'] != 'application/json; charset=utf-8' : print('content-type:' + res.headers['content-type']) res.close() time.sleep(60.0) continue json_text = res.text res.close() break return json_text def get_edinet_document_list_json_dir_path() : return '.' + os.sep + 'edinet_document_list_json' def get_edinet_document_list_json_file_path(t_date) : save_path = os.path.join( \ get_edinet_document_list_json_dir_path(), \ t_date + '.json' ) return save_path def save_edinet_document_list_json(t_date, json_text) : if not os.path.exists(get_edinet_document_list_json_dir_path()) : os.makedirs(get_edinet_document_list_json_dir_path()) save_path = get_edinet_document_list_json_file_path(t_date) value = json.loads(json_text) if value['metadata']['status'] != '200' : print(t_date + '.json status:' + value['metadata']['status']) sys.exit() file = open(save_path, "w") json.dump(value, file, indent = 4) file.close() t_date = '2023-01-25' print('edinetからドキュメントリストを取得') json_text = get_edinet_json_text(t_date) if not os.path.exists(get_edinet_document_list_json_file_path(t_date)) : print(get_edinet_document_list_json_file_path(t_date) +'を保存') save_edinet_document_list_json(t_date, json_text)
実行結果
edinetからドキュメントリストを取得 https://disclosure.edinet-fsa.go.jp/api/v1/documents.json?2023-01-25へリクエスト送信 .\edinet_document_list_json\2023-01-25.jsonを保存
最終的な処理内容
先ほどの内容に以下の処理を追加します
- 10年前から2日前までの日付を生成
- 各日付に対して処理を実行するように処理を修正
加えて、requests.getで例外が発生した場合もリトライするように処理を変更しました。通信が不安定な環境で実行すると使い物にならなかったので。
以下がソースコードです。
import requests import time import json import os import datetime from dateutil.relativedelta import relativedelta def get_edinet_json_text(date_str) : json_text = None params = { 'type' : 2, 'date' : date_str } url = 'https://disclosure.edinet-fsa.go.jp/api/v1/documents.json' retry_count = -1 while retry_count < 10 : retry_count = retry_count + 1 print(url + '?' + t_date + 'へリクエスト送信') time.sleep(2.0) try: res = requests.get(url, \ params=params, \ verify=False, \ timeout = 120.0) except requests.exceptions.RequestException as e: print('requests error' + str(e) ) time.sleep(60.0) continue if res.status_code != 200 : print('status_code:' + res.status_code) res.close() time.sleep(60.0) continue if res.headers['content-type'] != 'application/json; charset=utf-8' : print('content-type:' + res.headers['content-type']) res.close() time.sleep(60.0) continue json_text = res.text res.close() break return json_text def get_edinet_document_list_json_dir_path() : return '.' + os.sep + 'edinet_document_list_json' def get_edinet_document_list_json_file_path(t_date) : save_path = os.path.join( \ get_edinet_document_list_json_dir_path(), \ t_date + '.json' ) return save_path def save_edinet_document_list_json(t_date, json_text) : if not os.path.exists(get_edinet_document_list_json_dir_path()) : os.makedirs(get_edinet_document_list_json_dir_path()) save_path = get_edinet_document_list_json_file_path(t_date) value = json.loads(json_text) if value['metadata']['status'] != '200' : print(t_date + '.json status:' + value['metadata']['status']) sys.exit() file = open(save_path, "w") json.dump(value, file, indent = 4) file.close() #過去10年分の日付を生成し、各日付について処理 d_now = datetime.datetime.now() ten_years_ago_d_date = d_now - relativedelta(years=10) ten_years_ago_t_date = ten_years_ago_d_date.strftime('%Y-%m-%d') for trace_back_days in range(3700, 2, -1) : d_date = d_now - datetime.timedelta(days=trace_back_days) t_date = d_date.strftime('%Y-%m-%d') if t_date < ten_years_ago_t_date : continue if os.path.exists(get_edinet_document_list_json_file_path(t_date)) : print(get_edinet_document_list_json_file_path(t_date) +' is already exists. skip') continue print(get_edinet_document_list_json_file_path(t_date) +' processing') json_text = get_edinet_json_text(t_date) if json_text == None : print('json download fail. 処理中断') break save_edinet_document_list_json(t_date, json_text)
実行するとプログラムのカレントにディレクトリが生成され、JSONファイルが生成されます。
注意いただきたいのは、この実装では当日のJSONファイルをダウンロードしていません。なぜなら、当日分のJSONファイルは文書が公開されるとデータが追加されるからです。単純に既存のJSONのうち最も新しいファイルを上書きすればそれでよさそうですが実装していないです。
おわりに
とりあえず、「EDINETに存在するドキュメント一覧を取得する」処理としてはこれにて完成とさせていただきます。続いてはこのJSONファイルの内容をデータベースに保存して、検索する処理を作っていきます。
次回の記事はこちらです。
今回はここまでです。