はじめに
前回はEDINET上に存在するドキュメント一覧が書かれたJSONファイルをダウンロードしました。しかし、この形式のままだと目的の文書を検索するのに不便なので、今回はこのJSONファイル中のデータをDBに保存する処理を作成します。
開発環境
- windows 10 home
- python 3.7.4
- K2Editor(テキストエディタ) + コマンドプロンプト
使用したpythonの外部ライブラリ
少なくとも以下の外部ライブラリを利用しているのでインストールしていなければpipコマンドでインストールしてください。
- pysqlite3
JSONファイル中のドキュメント情報を読み出す
まず、ローカルに保存したJSONファイルを読み込んでみます。以下はEDINETからダウンロードできるJSONファイルの構造です。
EDINET API仕様書 p12~15より引用
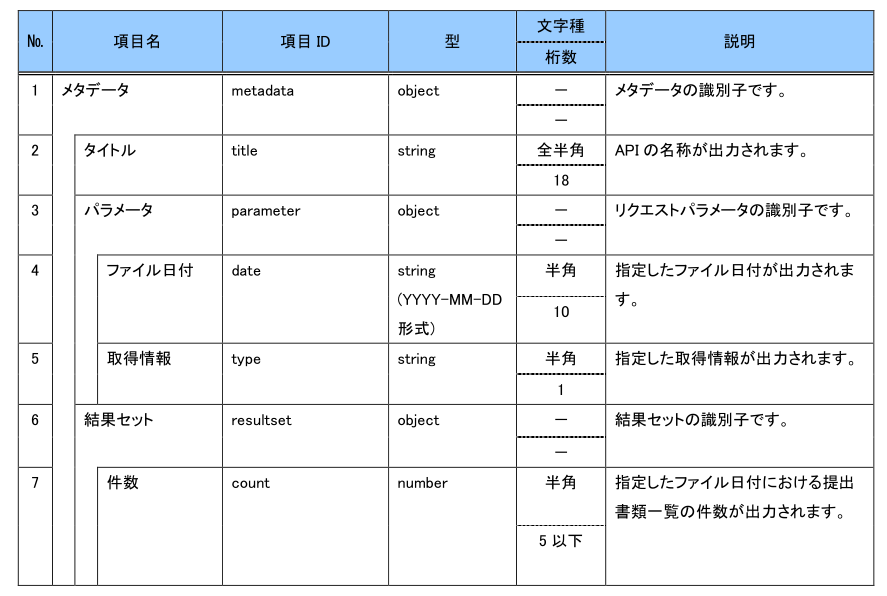
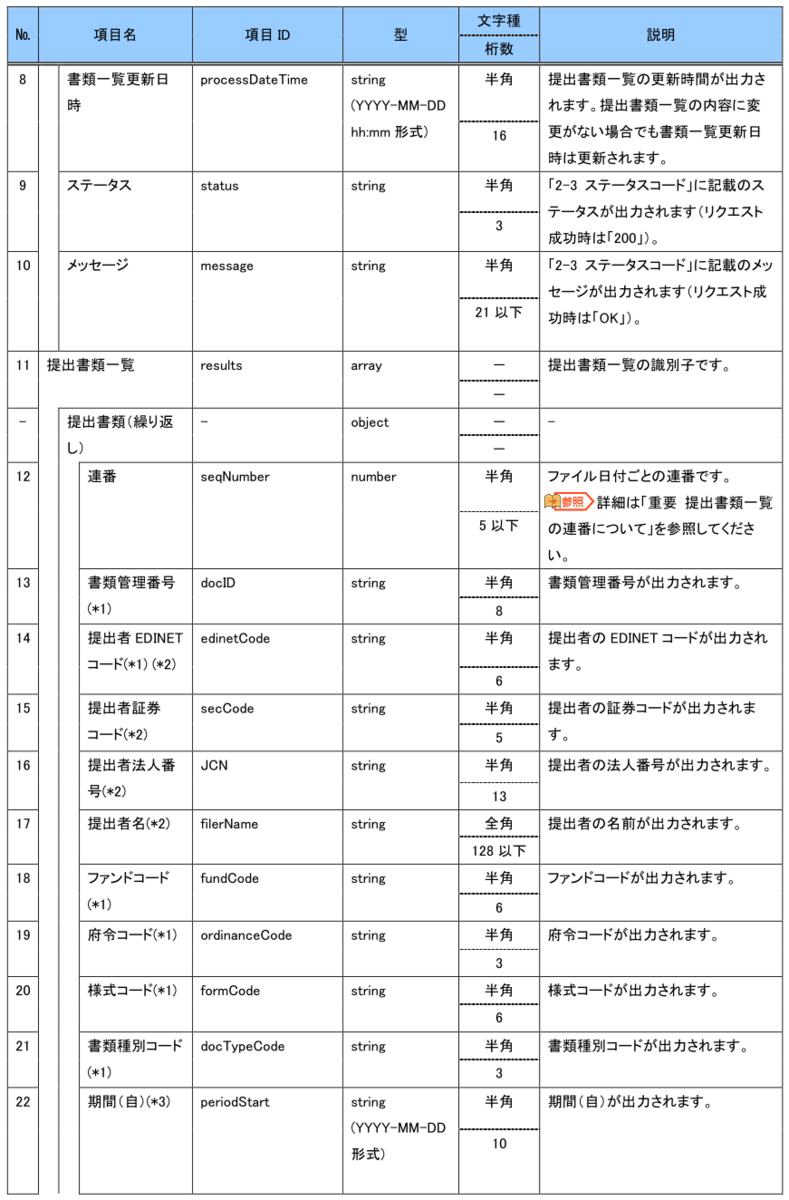
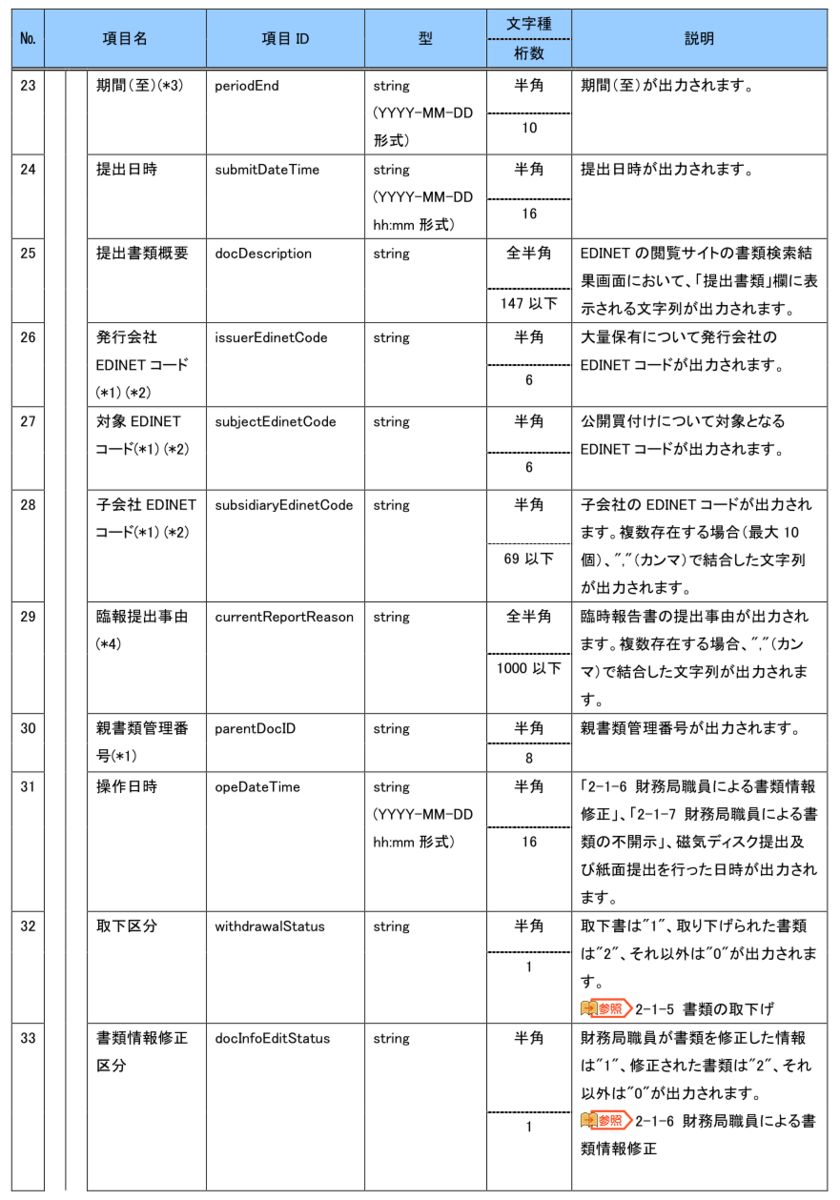
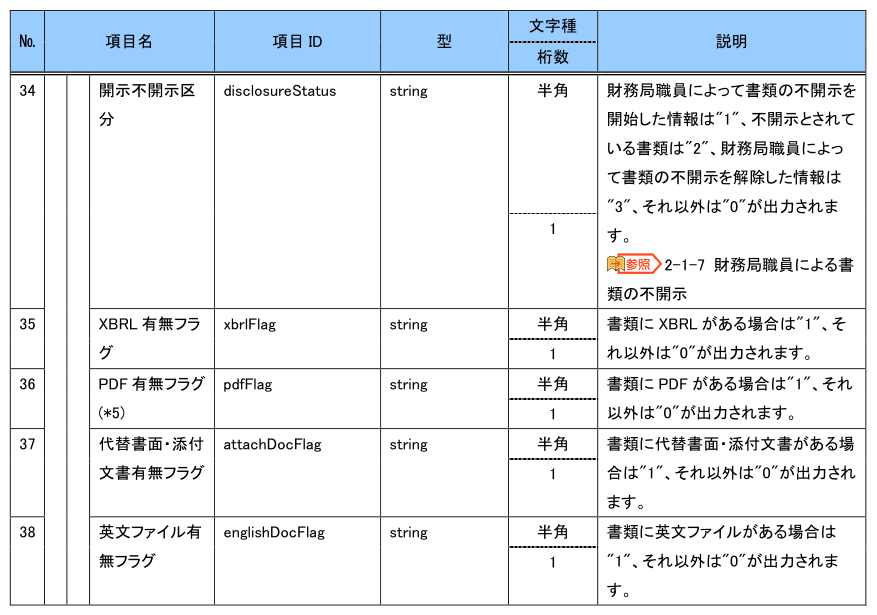
No1~10がJSONファイル中に含まれている文書数などのメタデータ、No11~が文書データになっています。仕様書ではNo38までしかありませんが、実際のJSONには文書データとしてcsvFlagとlefalStatusが追加されています。おそらく2023年の改定で追加になった項目でしょう。仕様書には記載がないですが、念のためこれもDBに保存してしまおうと思います。DBの構造を後から変えるのは非常に大変だからです。
念のため、JSON文書のstatusが正常(200)であることを確認します。誤ったデータが混入していると嫌だからです。
JSONファイルを1つ読み込んで、ドキュメント一覧を表示するコードはこんな感じになります。
import json value = None with open('.\\edinet_document_list_json\\2013-01-25.json', 'r') as f : value = json.load(f) if value['metadata']['status'] != '200' : sys.exit() count = int(value['metadata']['resultset']['count']) for index in range(0, count) : document_data_str = str(value['results'][index]['seqNumber']) + ',' + \ str(value['results'][index]['docID']) + ',' + \ str(value['results'][index]['edinetCode']) + ',' + \ str(value['results'][index]['secCode']) + ',' + \ str(value['results'][index]['JCN']) + ',' + \ str(value['results'][index]['filerName']) + ',' + \ str(value['results'][index]['fundCode']) + ',' + \ str(value['results'][index]['ordinanceCode']) + ',' + \ str(value['results'][index]['formCode']) + ',' + \ str(value['results'][index]['docTypeCode']) + ',' + \ str(value['results'][index]['periodStart']) + ',' + \ str(value['results'][index]['periodEnd']) + ',' + \ str(value['results'][index]['submitDateTime']) + ',' + \ str(value['results'][index]['docDescription']) + ',' + \ str(value['results'][index]['issuerEdinetCode']) + ',' + \ str(value['results'][index]['subjectEdinetCode']) + ',' + \ str(value['results'][index]['subsidiaryEdinetCode']) + ',' + \ str(value['results'][index]['currentReportReason']) + ',' + \ str(value['results'][index]['parentDocID']) + ',' + \ str(value['results'][index]['opeDateTime']) + ',' + \ str(value['results'][index]['withdrawalStatus']) + ',' + \ str(value['results'][index]['docInfoEditStatus']) + ',' + \ str(value['results'][index]['disclosureStatus']) + ',' + \ str(value['results'][index]['xbrlFlag']) + ',' + \ str(value['results'][index]['pdfFlag']) + ',' + \ str(value['results'][index]['attachDocFlag']) + ',' + \ str(value['results'][index]['englishDocFlag']) + ',' + \ str(value['results'][index]['csvFlag']) + ',' + \ str(value['results'][index]['legalStatus']) print('document[' + str(index) + '] = ' + document_data_str )
実行結果(一部を抜粋)
document[8] = 9,S000CO08,E04042,None,9180301006265,サーラ住宅株式会社, None,010,030000,120,2011-11-01,2012-10-31,2013-01-25 09:17, 有価証券報告書-第44期(2011/11/01-2012/10/31),None,None,None, None,None,None,0,0,0,1,1,1,0,1,2 document[33] = 34,S000CO5H,E01053,78560,7260001014438,萩原工業株式会社, None,010,030000,120,2011-11-01,2012-10-31,2013-01-25 11:50, 有価証券報告書-第50期(2011/11/01-2012/10/31),None,None,None, None,None,None,0,0,0,1,1,1,0,1,2 document[35] = 36,S000COB5,E04013,89170,8140001052787,ファースト住建株式会社, None,010,030000,120,2011-11-01,2012-10-31,2013-01-25 14:54, 有価証券報告書-第14期(2011/11/01-2012/10/31),None,None,None, None,None,None,0,0,0,1,1,1,0,1,2
ドキュメント情報を保存するDBとテーブルの作成
ここではSQLiteを使ってJSONファイルのドキュメント情報を保存します。SQLiteで生成されるdbはローカルに保存されるファイルであり、バックアップも簡単です。DB中のテーブルはドキュメント情報を全て保存できるように作成します。仕様書を読む限り、各要素は基本的に文字列なので文字列として保存します。
doc_idについてはEDINETのAPI仕様書に「EDINET で開示書類ごとに付与された一意の番号です」と記載があるため、主キーとして設定します。
DBを作成し、データ保存用のテーブルを生成するコードです。
import sqlite3 conn = sqlite3.connect('edinetfile.db') cur = conn.cursor() cur.execute(''' CREATE TABLE IF NOT EXISTS edinet_document( seq_number TEXT, doc_id TEXT PRIMARY KEY, edinet_code TEXT, sec_code TEXT, jcn TEXT, filer_name TEXT, fund_code TEXT, ordinance_code TEXT, form_code TEXT, doc_type_code TEXT, period_start TEXT, period_end TEXT, submit_date_time TEXT, doc_description TEXT, issuer_edinet_code TEXT, subject_edinet_code TEXT, subsidiary_edinet_code TEXT, current_report_reason TEXT, parent_doc_id TEXT, ope_date_time TEXT, withdrawal_status TEXT, doc_info_edit_status TEXT, disclosure_status TEXT, xbrl_flag TEXT, pdf_flag TEXT, attach_doc_flag TEXT, english_doc_flag TEXT, csv_flag TEXT, legal_status TEXT) ''') conn.commit() cur.close() conn.close()
実行するとカレントにedinetfile.dbというファイルが作成されます。これがDBです。
DBの内容を「DB Browser for SQLite」というアプリから確認できます。Windows用のアプリです。商用は有料みたいですが個人利用なら問題ないです。
以下は確認結果です。プログラムで記載した通りのテーブルが作成されています。
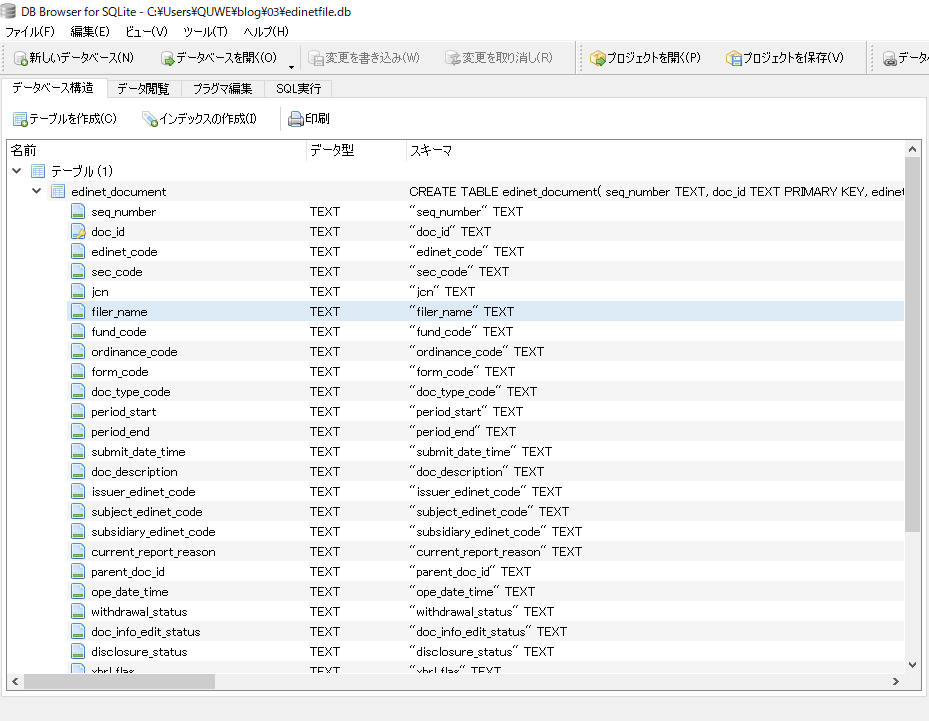
DBにドキュメント情報を保存する
作ったDBにドキュメント情報を保存します。この処理をローカルのJSONファイル全てに対して繰り返せばよいです。
少し面倒なのは、ドキュメント文書の付随情報(例えば提出書類概要)に変更があった場合、EDINET上に同じdoc_idのデータが複数存在してしまいます。EDINET APIの仕様書を読む限り、後に存在しているデータを正として扱えば問題なさそうだったので、重複が発生した場合は後優先でデータを保存するようにしています。ただ、doc_idから保存できるXBRL文書の内容に差異はないみたいなのでそこまで気を使う必要はないかもしれません。
また、EDINET上に存在しないドキュメントのデータはDBに保存しないようにしています。提出者 EDINETコードが未設定で、XBRLとPDFがともに存在しない文書をそのように判定しています。
以下がDBにドキュメント情報を保存する完全なコードです。
import sqlite3 import glob import os import json conn = sqlite3.connect('edinetfile.db') cur = conn.cursor() cur.execute(''' CREATE TABLE IF NOT EXISTS edinet_document( seq_number TEXT, doc_id TEXT PRIMARY KEY, edinet_code TEXT, sec_code TEXT, jcn TEXT, filer_name TEXT, fund_code TEXT, ordinance_code TEXT, form_code TEXT, doc_type_code TEXT, period_start TEXT, period_end TEXT, submit_date_time TEXT, doc_description TEXT, issuer_edinet_code TEXT, subject_edinet_code TEXT, subsidiary_edinet_code TEXT, current_report_reason TEXT, parent_doc_id TEXT, ope_date_time TEXT, withdrawal_status TEXT, doc_info_edit_status TEXT, disclosure_status TEXT, xbrl_flag TEXT, pdf_flag TEXT, attach_doc_flag TEXT, english_doc_flag TEXT, csv_flag TEXT, legal_status TEXT, json_date TEXT) ''') conn.commit() cur.close() conn.close() conn = sqlite3.connect('edinetfile.db') conn.row_factory = sqlite3.Row cur = conn.cursor() local_json_files = glob.glob('.' + os.sep + 'edinet_document_list_json' + os.sep +'*.json') local_json_files.sort() for local_json_file in local_json_files : json_date = local_json_file.split(os.sep)[-1].replace('.json', '') print( local_json_file + ' processing' ) value = None with open(local_json_file, 'r') as f : value = json.load(f) if value['metadata']['status'] != '200' : sys.exit() count = int(value['metadata']['resultset']['count']) for index in range(0, count) : #edinetCodeがnullでxbrlもpdfも存在しないファイルは #削除された文書と考えてよい #また、データの使用目的からもそのような文書は必要ない if value['results'][index]['edinetCode'] == None and \ value['results'][index]['xbrlFlag'] == '0' and \ value['results'][index]['pdfFlag'] == '0' : continue ins_data = (str(value['results'][index]['seqNumber']), \ str(value['results'][index]['docID']), \ str(value['results'][index]['edinetCode']), \ str(value['results'][index]['secCode']), \ str(value['results'][index]['JCN']), \ str(value['results'][index]['filerName']), \ str(value['results'][index]['fundCode']), \ str(value['results'][index]['ordinanceCode']), \ str(value['results'][index]['formCode']), \ str(value['results'][index]['docTypeCode']), \ str(value['results'][index]['periodStart']), \ str(value['results'][index]['periodEnd']), \ str(value['results'][index]['submitDateTime']), \ str(value['results'][index]['docDescription']), \ str(value['results'][index]['issuerEdinetCode']), \ str(value['results'][index]['subjectEdinetCode']), \ str(value['results'][index]['subsidiaryEdinetCode']), \ str(value['results'][index]['currentReportReason']), \ str(value['results'][index]['parentDocID']), \ str(value['results'][index]['opeDateTime']), \ str(value['results'][index]['withdrawalStatus']), \ str(value['results'][index]['docInfoEditStatus']), \ str(value['results'][index]['disclosureStatus']), \ str(value['results'][index]['xbrlFlag']), \ str(value['results'][index]['pdfFlag']), \ str(value['results'][index]['attachDocFlag']), \ str(value['results'][index]['englishDocFlag']), \ str(value['results'][index]['csvFlag']), \ str(value['results'][index]['legalStatus']), \ json_date) ins = '''INSERT INTO edinet_document ( seq_number, doc_id, edinet_code, sec_code, jcn, filer_name, fund_code, ordinance_code, form_code, doc_type_code, period_start, period_end, submit_date_time, doc_description, issuer_edinet_code, subject_edinet_code, subsidiary_edinet_code, current_report_reason, parent_doc_id, ope_date_time, withdrawal_status, doc_info_edit_status, disclosure_status, xbrl_flag, pdf_flag, attach_doc_flag, english_doc_flag, csv_flag, legal_status, json_date) VALUES(?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, \ ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)''' replace_flag = False try: cur.execute(ins, ins_data) #文書の修正等の理由からdoc_idが同一なデータが存在する場合がある #この場合、xbrlやpdfに差異はないが、文書に関する説明やフラグに #変更が生じるため、新しいデータを正として置き換える必要がある except sqlite3.IntegrityError as e: cur.execute('SELECT * FROM edinet_document WHERE doc_id=?', \ (str(value['results'][index]['docID']),) ) row = cur.fetchone() #jsonファイルの日付が新しいものを優先する if row['json_date'] < json_date : replace_flag = True #日付が同じなら連番が大きいものを優先する elif row['json_date'] == json_date and \ int( row['seq_number'] ) < int( value['results'][index]['seqNumber']) : replace_flag = True if replace_flag == True : print('replace record ' + row['json_date'] + ',' + row['seq_number'] + \ ' to ' + json_date + ',' + str( value['results'][index]['seqNumber'] ) ) ins = '''REPLACE INTO edinet_document ( seq_number, doc_id, edinet_code, sec_code, jcn, filer_name, fund_code, ordinance_code, form_code, doc_type_code, period_start, period_end, submit_date_time, doc_description, issuer_edinet_code, subject_edinet_code, subsidiary_edinet_code, current_report_reason, parent_doc_id, ope_date_time, withdrawal_status, doc_info_edit_status, disclosure_status, xbrl_flag, pdf_flag, attach_doc_flag, english_doc_flag, csv_flag, legal_status, json_date) VALUES(?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, \ ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)''' cur.execute(ins, ins_data) conn.commit() cur.close() conn.close()
実行結果
.\edinet_document_list_json\2013-01-25.json processing .\edinet_document_list_json\2013-01-26.json processing .\edinet_document_list_json\2013-01-27.json processing .\edinet_document_list_json\2013-01-28.json processing .\edinet_document_list_json\2013-01-29.json processing .\edinet_document_list_json\2013-01-30.json processing .\edinet_document_list_json\2013-01-31.json processing replace record 2013-01-31,12 to 2013-01-31,29 .\edinet_document_list_json\2013-02-01.json processing .\edinet_document_list_json\2013-02-02.json processing .\edinet_document_list_json\2013-02-03.json processing .\edinet_document_list_json\2013-02-04.json processing .\edinet_document_list_json\2013-02-05.json processing ・・・
また、カレントにedinetfile.dbというファイルができます。大体120MBくらいの大きさです。以下はDBの中身です。
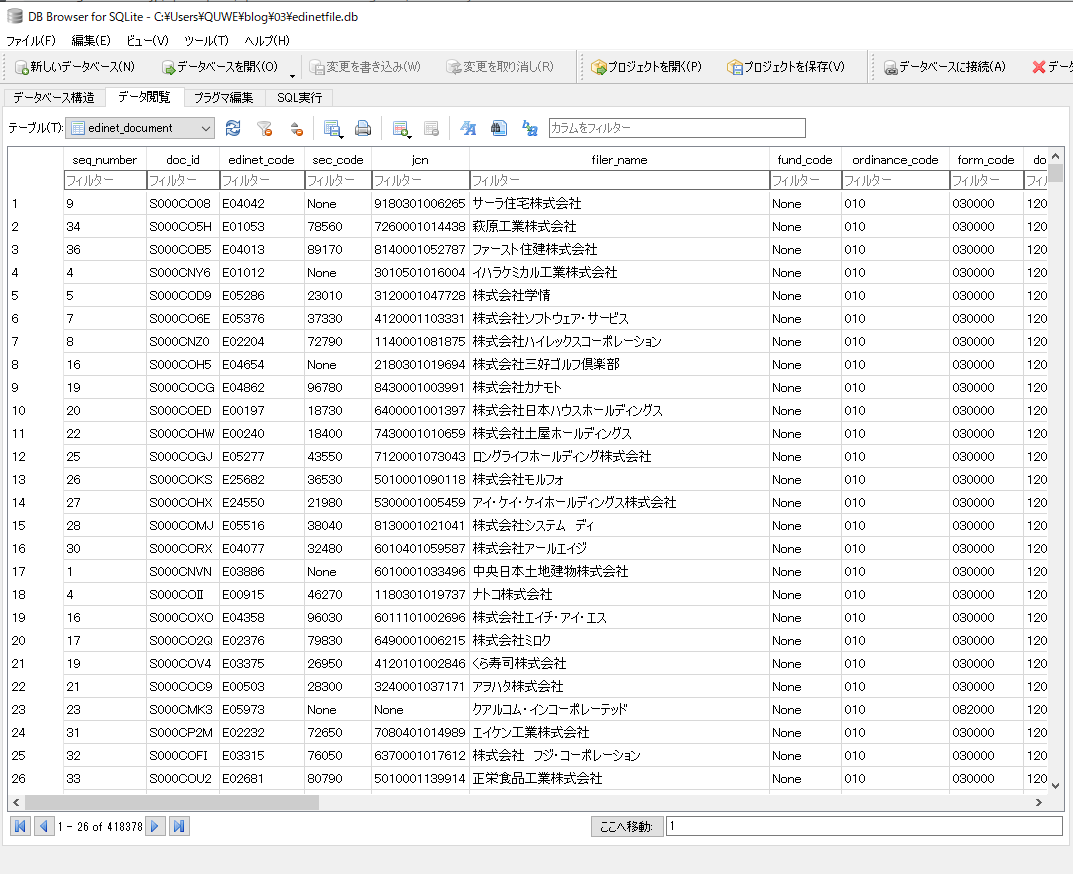
おわりに
これでEDINET上に存在する文書の情報をデータベースにすることが出来ました。次回はデータベースの検索処理を作っていくつもりです。
次回の記事です。
www.quwechan.com
今回はここまでです。