はじめに
前回はEDINET上に存在するドキュメントの一覧情報をDBにしました。今回はこのDBをつかって
- 自分が欲しいドキュメント(例えば竹本容器の有価証券報告書)を検索する
- 検索結果をもとにXBRLをEDINETからダウンロードして保存する
をやっていきます。
今回はとりあえず竹本容器の有価証券報告書のXBRLをダウンロードします。
開発環境
- windows 10 home
- python 3.7.4
- K2Editor(テキストエディタ) + コマンドプロンプト
使用したpythonの外部ライブラリ
少なくとも以下の外部ライブラリを利用しているのでインストールしていなければpipコマンドでインストールしてください。
- pysqlite3
- requests
DBから竹本容器の有価証券報告書を検索する
DBから竹本容器の有価証券報告書を検索するためには
- 提出者のEDINETコード
- 書類種別コード
の2つの情報が必要です。
EDINETコードの一覧はEDINETの公式ページにダウンロードリンクがあります。
上記リンク先ページの最下部に次のような表示があるのでcsvファイルをダウンロードしましょう。
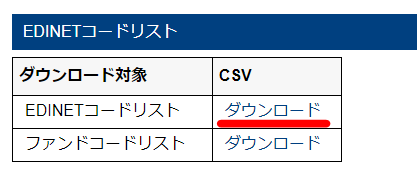
以下はcsvファイルの中身です。必要な部分のみ抜粋しています。

EDINETコードは会社名や証券コードで検索することで知ることが出来ます。竹本容器のEDINETコードがE31037であることがわかりました。
書類種別コードはEDINET APIの仕様書に記載があります。有価証券報告書の書類種別コードは120です。
EDINET API仕様書 p49~50より引用


EDINETコードと書類種別コードを使ってDBを検索するコードです。
import sqlite3 conn = sqlite3.connect('edinetfile.db') conn.row_factory = sqlite3.Row cur = conn.cursor() cur.execute('SELECT * FROM edinet_document \ WHERE edinet_code=? AND doc_type_code=? AND xbrl_flag=?',\ ('E31037','120', '1')) row = cur.fetchone() while row != None : print(row['doc_id'] + ',' + row['filer_name'] + ',' + row['doc_description']) row = cur.fetchone() cur.close() conn.close()
実行結果(一部を抜粋)
S1004F0Z,竹本容器株式会社,有価証券報告書-第64期(2014/01/01-2014/12/31) S10079H3,竹本容器株式会社,有価証券報告書-第65期(2015/01/01-2015/12/31) S1009ZCG,竹本容器株式会社,有価証券報告書-第66期(2016/01/01-2016/12/31) S100CNNO,竹本容器株式会社,有価証券報告書-第67期(平成29年1月1日-平成29年12月31日) S100FHET,竹本容器株式会社,有価証券報告書-第68期(平成30年1月1日-平成30年12月31日) S100IAQ0,竹本容器株式会社,有価証券報告書-第69期(平成31年1月1日-令和1年12月31日) S100L1E8,竹本容器株式会社,有価証券報告書-第70期(令和2年1月1日-令和2年12月31日) S100NROE,竹本容器株式会社,有価証券報告書-第71期(令和3年1月1日-令和3年12月31日)
欲しい文書の一覧を取得することが出来ました。ここで取得した文書の書類管理番号(S1004F0Zのような文字列、以降doc_idと記載する)をつかってEDINET API経由でXBRLをダウンロードすることが出来ます。
EDINET APIを使ってXBRLをダウンロードする
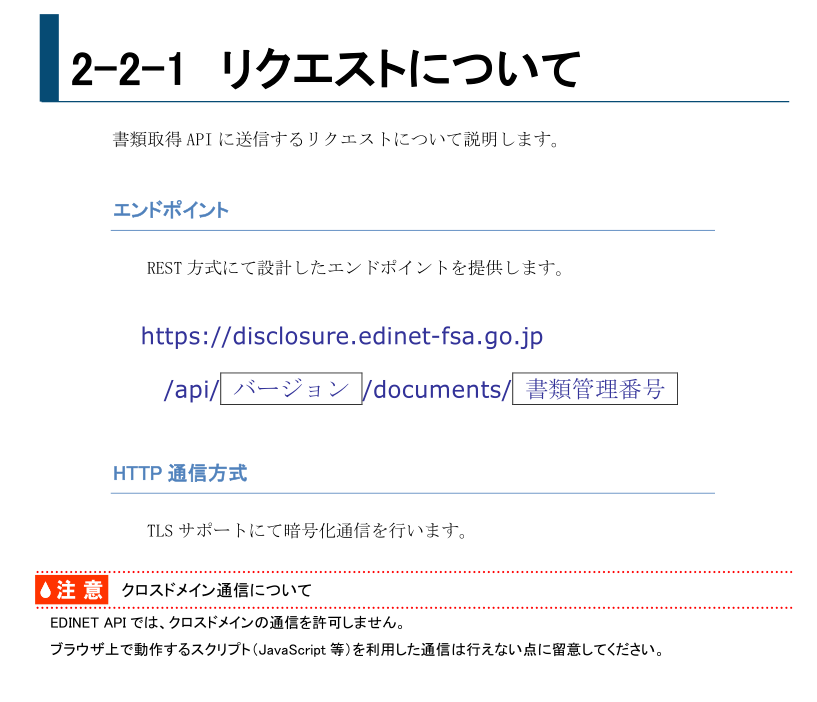
XBRLをダウンロードするためにはサーバに対してHTTPリクエスト(GETメソッド)を送る必要があります。エンドポイントとかリクエストパラメータはEDINET APIの仕様書に記載があります。
EDINET APIの仕様書 p39~41より引用

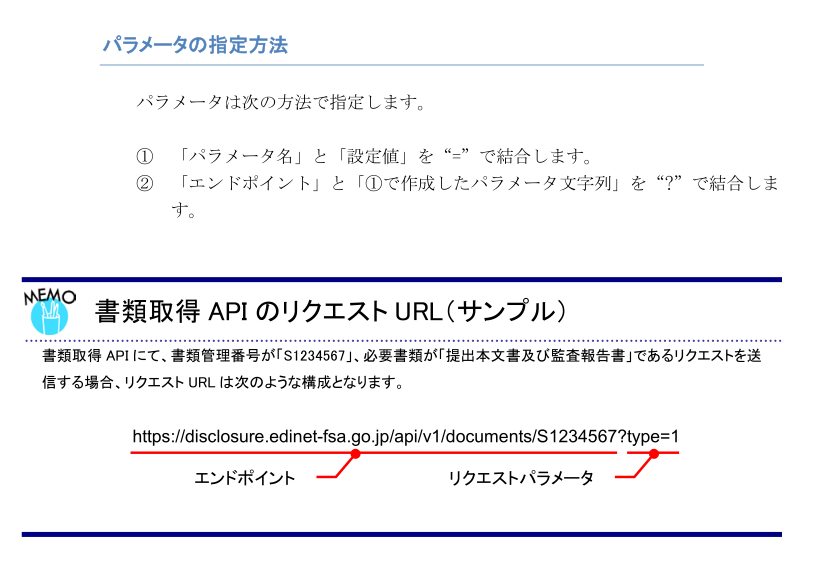
また、サーバレスポンスのレスポンスヘッダ(content-type)の仕様は以下の通りです。
EDINET APIの仕様書 p42より引用

ステータスコードは200のみ、レスポンスヘッダ(content-type)は「application/octet-stream」のみを正常として、他はすべてエラーとします。
レスポンスヘッダ(content-type)が「application/json; charset=utf-8」である場合、JSONがサーバから返され、JSON中のステータス値によってエラーの内容が判別できるようです。
EDINET APIの仕様書 p45より引用

今回はサーバから返されたJSONファイルの中身まで詳しく調べることはしていません。サーバから正常なレスポンスがくるまで何回か試行して、それでダメならエラーとしています。
XBRLを1ファイルだけダウンロードするコードです。
import os import requests import time def get_xbrl_dir_path() : return '.' + os.sep + 'xbrl' def get_xbrl_file_path(doc_id) : return os.path.join( get_xbrl_dir_path(), doc_id + '.zip' ) def download_edinet_xbrl(doc_id) : download_result = False params = { 'type' : 1 } url = 'https://disclosure.edinet-fsa.go.jp/api/v1/documents/' + doc_id retry_count = -1 while retry_count < 10 : retry_count = retry_count + 1 print(url + 'へリクエスト送信') time.sleep(2.0) try: res = requests.get(url, \ params=params, \ verify=False, \ timeout = 120.0) except requests.exceptions.RequestException as e: print('requests error' + str(e) ) time.sleep(10.0) continue if res.status_code != 200 : print('status_code:' + res.status_code) res.close() time.sleep(10.0) continue if res.headers['content-type'] != 'application/octet-stream' : print('content-type:' + res.headers['content-type']) res.close() time.sleep(10.0) continue #XBRLをローカルに保存する if not os.path.exists( get_xbrl_dir_path() ) : os.makedirs( get_xbrl_dir_path() ) with open(get_xbrl_file_path(doc_id), 'wb') as f : for chunk in res.iter_content(chunk_size=1024) : f.write(chunk) res.close() download_result = True break return download_result doc_id = 'S100NROE' result = download_edinet_xbrl(doc_id) if result == False : print( doc_id + ' download fail' ) print( doc_id + ' download success' )
実行結果
https://disclosure.edinet-fsa.go.jp/api/v1/documents/S100NROEへリクエスト送信 S100NROE download success
カレントのxbrlディレクトリにXBRLファイルのzipが生成されます。

zipファイルの健全性チェックはしていません。
もしするならば
- pythonで解凍できること
- 内部にXBRLインスタンスファイル(拡張子 .xbrl)が存在していること
を確認すれば十分だと思います。
今のところ、過去5年分のデータについては上記のチェックで問題なく使えています。
DBの検索結果をもとにXBRLをダウンロードする
DBの検索結果から得られたすべてのdoc_idに対してダウンロードを実施します。
以下がコードです。
import sqlite3 import requests import time import os class EdinetDocumentInfoRecord() : def __init__(self, seq_number, \ doc_id, \ edinet_code, \ sec_code, \ jcn, \ filer_name, \ fund_code, \ ordinance_code, \ form_code, \ doc_type_code, \ period_start, \ period_end, \ submit_date_time, \ doc_description, \ issuer_edinet_code, \ subject_edinet_code, \ subsidiary_edinet_code, \ current_report_reason, \ parent_doc_id, \ ope_date_time, \ withdrawal_status, \ doc_info_edit_status, \ disclosure_status, \ xbrl_flag, \ pdf_flag, \ attach_doc_flag, \ english_doc_flag, \ csv_flag, \ legal_status, \ json_date): self.__seq_number=seq_number self.__doc_id=doc_id self.__edinet_code=edinet_code self.__sec_code=sec_code self.__jcn=jcn self.__filer_name=filer_name self.__fund_code=fund_code self.__ordinance_code=ordinance_code self.__form_code=form_code self.__doc_type_code=doc_type_code self.__period_start=period_start self.__period_end=period_end self.__submit_date_time=submit_date_time self.__doc_description=doc_description self.__issuer_edinet_code=issuer_edinet_code self.__subject_edinet_code=subject_edinet_code self.__subsidiary_edinet_code=subsidiary_edinet_code self.__current_report_reason=current_report_reason self.__parent_doc_id=parent_doc_id self.__ope_date_time=ope_date_time self.__withdrawal_status=withdrawal_status self.__doc_info_edit_status=doc_info_edit_status self.__disclosure_status=disclosure_status self.__xbrl_flag=xbrl_flag self.__pdf_flag=pdf_flag self.__attach_doc_flag=attach_doc_flag self.__english_doc_flag=english_doc_flag self.__csv_flag=csv_flag self.__legal_status=legal_status self.__json_date=json_date def get_doc_id(self) : return self.__doc_id def get_edinet_code(self) : return self.__edinet_code def get_filer_name(self) : return self.__filer_name def get_doc_description(self) : return self.__doc_description def get_xbrl_dir_path() : return '.' + os.sep + 'xbrl' def get_xbrl_file_path(doc_id) : return os.path.join( get_xbrl_dir_path(), doc_id + '.zip' ) def download_edinet_xbrl(doc_id) : download_result = False params = { 'type' : 1 } url = 'https://disclosure.edinet-fsa.go.jp/api/v1/documents/' + doc_id retry_count = -1 while retry_count < 10 : retry_count = retry_count + 1 print(url + 'へリクエスト送信') time.sleep(2.0) try: res = requests.get(url, \ params=params, \ verify=False, \ timeout = 120.0) except requests.exceptions.RequestException as e: print('requests error' + str(e) ) time.sleep(10.0) continue if res.status_code != 200 : print('status_code:' + res.status_code) res.close() time.sleep(10.0) continue if res.headers['content-type'] != 'application/octet-stream' : print('content-type:' + res.headers['content-type']) res.close() time.sleep(10.0) continue #XBRLをローカルに保存する if not os.path.exists( get_xbrl_dir_path() ) : os.makedirs( get_xbrl_dir_path() ) with open(get_xbrl_file_path(doc_id), 'wb') as f : for chunk in res.iter_content(chunk_size=1024) : f.write(chunk) res.close() download_result = True break return download_result #検索結果を保存する edinet_document_info_record_list = list() conn = sqlite3.connect('edinetfile.db') conn.row_factory = sqlite3.Row cur = conn.cursor() cur.execute('SELECT * FROM edinet_document \ WHERE edinet_code=? AND doc_type_code=? AND xbrl_flag=?',\ ('E31037','120', '1')) row = cur.fetchone() while row != None : search_result = EdinetDocumentInfoRecord( row['seq_number'],\ row['doc_id'],\ row['edinet_code'],\ row['sec_code'],\ row['jcn'],\ row['filer_name'],\ row['fund_code'],\ row['ordinance_code'],\ row['form_code'],\ row['doc_type_code'],\ row['period_start'],\ row['period_end'],\ row['submit_date_time'],\ row['doc_description'],\ row['issuer_edinet_code'],\ row['subject_edinet_code'],\ row['subsidiary_edinet_code'],\ row['current_report_reason'],\ row['parent_doc_id'],\ row['ope_date_time'],\ row['withdrawal_status'],\ row['doc_info_edit_status'],\ row['disclosure_status'],\ row['xbrl_flag'],\ row['pdf_flag'],\ row['attach_doc_flag'],\ row['english_doc_flag'],\ row['csv_flag'],\ row['legal_status'],\ row['json_date']) edinet_document_info_record_list.append(search_result) row = cur.fetchone() cur.close() conn.close() #XBRLをダウンロードする for search_result in edinet_document_info_record_list : print(search_result.get_filer_name() + ',' + \ search_result.get_doc_id() + ',' + \ search_result.get_doc_description()) doc_id = search_result.get_doc_id() if os.path.exists( get_xbrl_file_path(doc_id) ) : print('xbrl is already exists. pass') continue result = download_edinet_xbrl(doc_id) if result == False : print( doc_id + ' download fail' ) print( doc_id + ' download success' )
実行結果
竹本容器株式会社,S1004F0Z,有価証券報告書-第64期(2014/01/01-2014/12/31) https://disclosure.edinet-fsa.go.jp/api/v1/documents/S1004F0Zへリクエスト送信 S1004F0Z download success 竹本容器株式会社,S10079H3,有価証券報告書-第65期(2015/01/01-2015/12/31) https://disclosure.edinet-fsa.go.jp/api/v1/documents/S10079H3へリクエスト送信 S10079H3 download success 竹本容器株式会社,S1009ZCG,有価証券報告書-第66期(2016/01/01-2016/12/31) https://disclosure.edinet-fsa.go.jp/api/v1/documents/S1009ZCGへリクエスト送信 S1009ZCG download success ・・・
おわりに
これで自分が欲しいXBRLをEDINETからダウンロードできるようになりました。
EDINET上に存在するすべてのXBRLをダウンロードするなら
- ダウンロード時のエラー処理をもう少し細かく行い、リトライの可否を判定する
- ZIPの健全性チェックを行う
- ダウンロード結果をDBに保存して、必要に応じて再度リトライする
などしなくてはなりませんが、ここではそこまでしていません。
別にそこまでしなくても、XBRLの分析処理はできるのでいいかなと思っています。一応、データの蓄積はやっているので機会があれば記事にするかもしれません。
次回からXBRLの構造解析をしていきたいと思います。具体的には有価証券報告書内の数値データを取得します。ただ、数値を取得するまでは道のりが長いので少しづつやっていくことになると思います。
次回の記事です。
今回はここまでです。