はじめに
前回はTDnetから決算短信のXBRLをダウンロードする方法について説明しました。
今回は東証上場会社情報サービスから決算短信のXBRLをダウンロードしてみます。
TDnetは過去1か月分の開示しか入手できませんが、東証会社情報サービスではより過去の開示も入手可能です。したがって、当日の最新の開示が欲しければTDnet、過去の開示が欲しければ東証会社情報サービスというように使い分ける必要があります。

東証上場会社情報サービスから決算短信のXBRLをダウンロードする
方針
XBRLの一覧にたどり着くまでのページ遷移
以下は東証上場会社情報サービスの検索画面です。このページで検索条件を入力し、検索ボタンを押すことで開示を取得することが可能です。

銘柄コードを入力し、検索ボタンを押すと検索結果ページが表示されます。
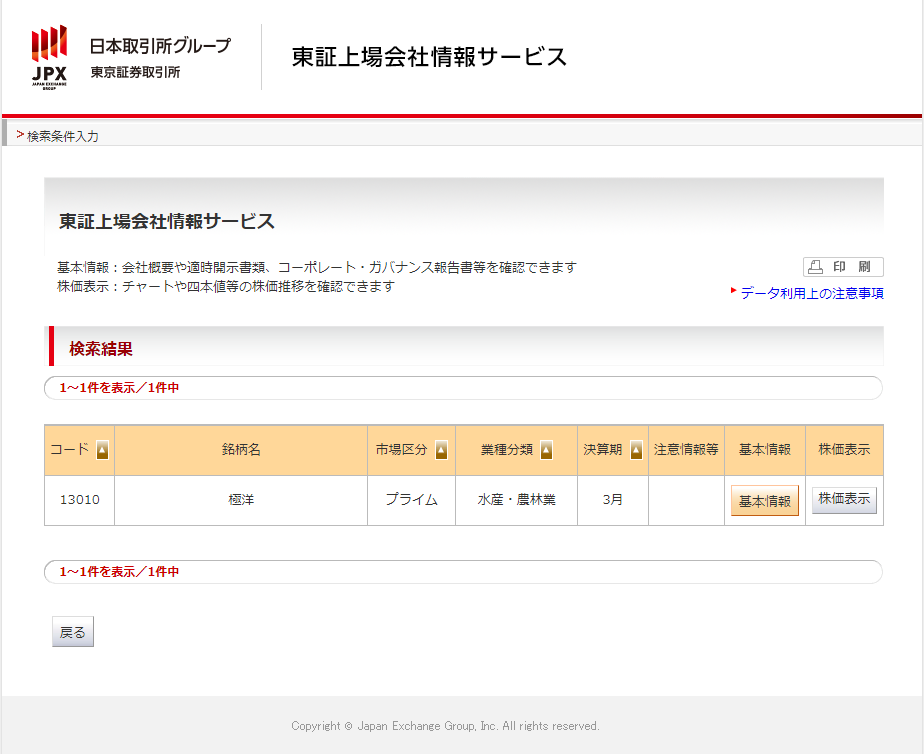
検索結果ページの該当する銘柄の基本情報ボタンを押すと該当銘柄のページに遷移します。

その後は
- 適時開示情報タブをクリック
- 「情報を閲覧する場合はこちら」ボタンをクリック
といった流れでページ遷移することで、必要なXBRLの一覧までたどり着けます。
適時開示情報タブをクリック後
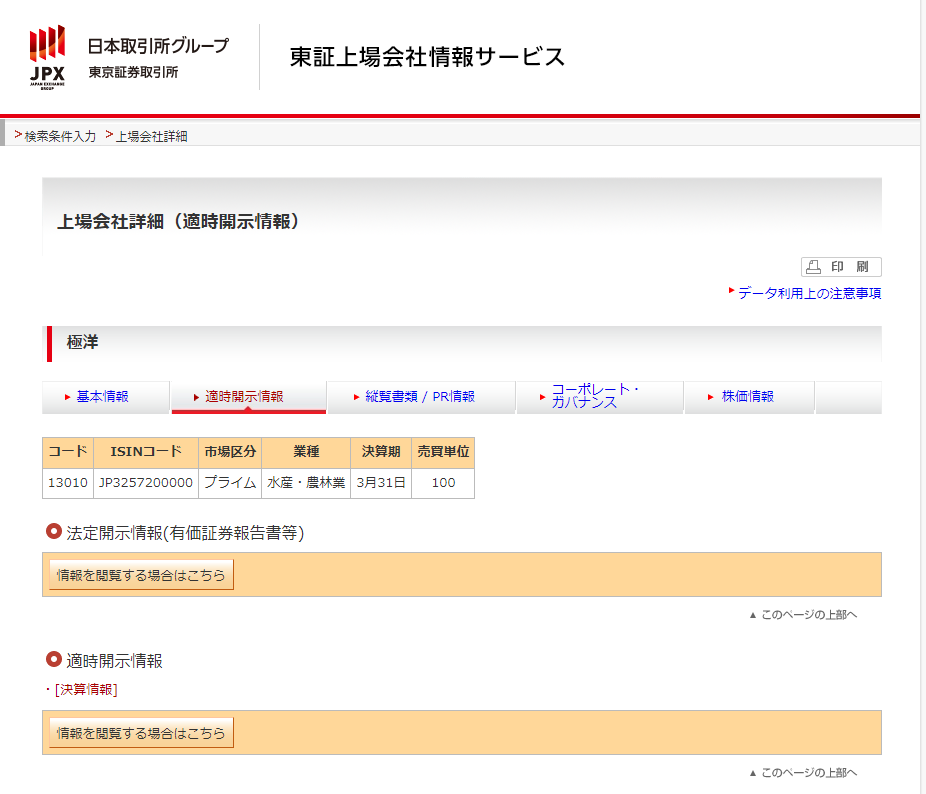
「情報を閲覧する場合はこちら」ボタンをクリック後
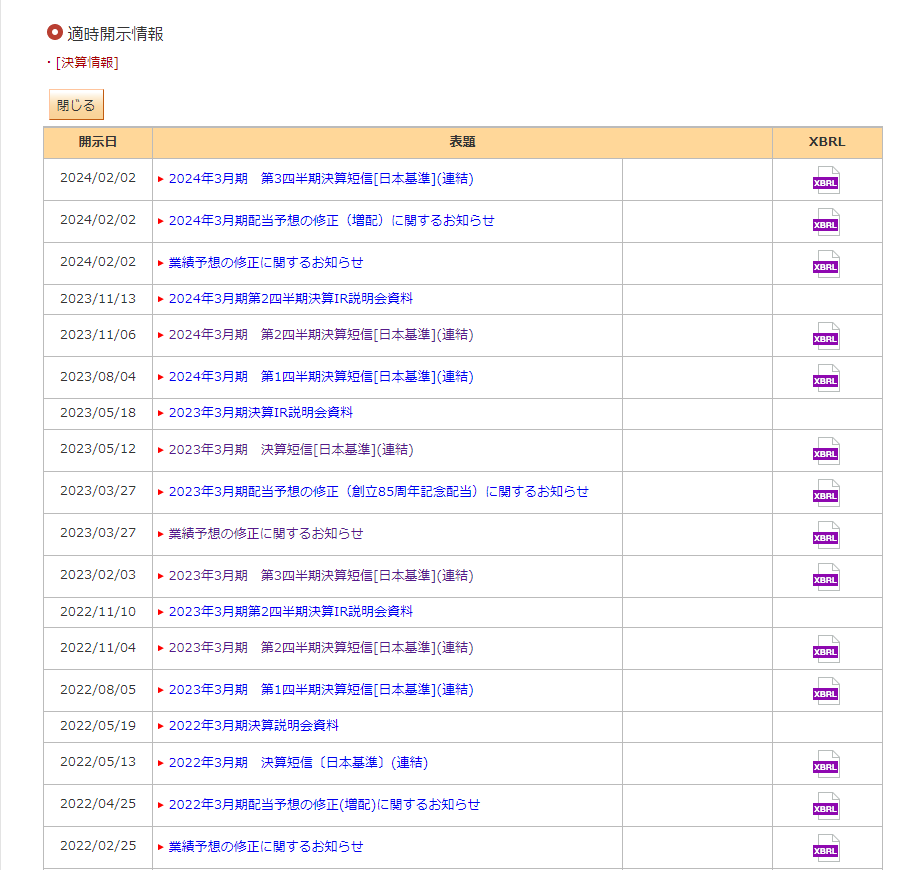
これらのページ遷移をプログラム上で実現する必要があります。
ページ遷移の実現方法
東証上場会社情報サービスではTDnetのように遷移先ページのhtmlソースがサーバ上に存在しているわけではないので、単純に特定のurlに対してGETリクエストを送信するといったやり方は使えませんでした。
ページソースを読んでみると「検索」ボタンや「基本情報」ボタンが押されると特定のフォームデータがサーバにPOSTされてるだけのようなので、単純にPOSTリクエストを送信してやればページ遷移後のhtmlソースをサーバから取得可能です。ちなみに対象となるフォームタグのaction属性は検索ボタンが「/tseHpFront/JJK010010Action.do」、基本情報ボタンが「/tseHpFront/JJK010030Action.do」のように異なるため、POSTリクエストの送信先は必要に応じて変更してやる必要があります。ここら辺はページソース(htmlとjavascript)を読めばわかります。
クロームの開発者ツールでブラウザーの通信を表示するとPOSTリクエストの送信先やリクエストヘッダー、送信データが何かを確認できます。
POSTリクエストの送信先とリクエストヘッダーの例
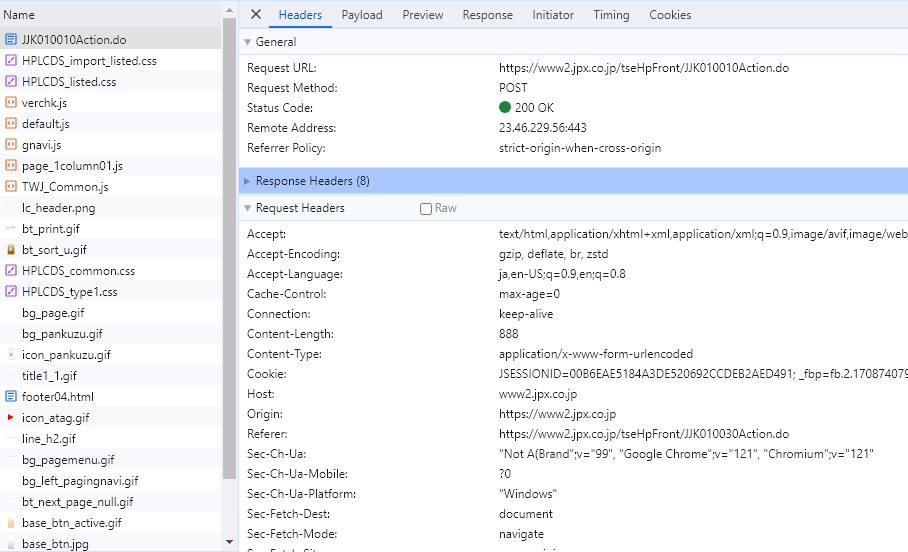
送信データ

リクエストヘッダー(レスポンスヘッダ―も)のconnectionがkeep-aliveとなっているので、同一セッションでPOSTリクエストを送信する必要があります。POSTリクエストでどんなデータを送ればいいのかについては、わたしがそこら辺をよく理解できてないため開発者ツールで確認できた形式でデータを作ってやることにします。いろいろ考えるのは大変そうなので検索には銘柄コードのみを用いています。
また、「基本情報」ボタンを押し、該当銘柄の情報ページに遷移した後はjavascriptによってページ内の要素の表示・非表示が切り替えられるだけで新たなサーバアクセスは発生していませんでした。したがって、該当銘柄の情報ページのソースを取得後はhtmlパーサを使って解析すればいいだけです。
htmlソースの解析
情報ページには法定開示、適時開示、縦覧書類の3種の開示がまとめられています。このうち法廷開示はEDINET上のpdfリンクが張られているだけであり、今回は東証上場会社情報サービス固有のデータが欲しいので無視します。
欲しいデータは特定のidが設定されたtableタグ内に記載されており、idは以下のような命名規則となっています。
| 開示種別 | tableタグのid | 備考 |
|---|---|---|
| 法廷開示 | closeUpHotei | |
| 適時開示 | closeUpKaiji* | *は適当な数字 |
| 縦覧書類 | closeUpFili* | *は適当な数字 |
したがって、idが「closeUpKaiji*」「closeUpFili*」となるようなtableタグを取得してやればいいです。
ここでは開示の
- 開示日
- 表題
- pdfのurl
- xbrlのurl
を取得します。
実装
検索結果ページの取得
検索トップページにGETリクエストを送信後、同一セッションでJJK010010Action.doに対してデータをPOSTします。データの形式はあらかじめクロームの開発者ツールを使って確認しておきます。
import requests from bs4 import BeautifulSoup import time with requests.Session() as session : #まず、検索ページのトップにアクセスする session.get('https://www2.jpx.co.jp/tseHpFront/JJK010010Action.do') time.sleep(1) #検索のためのPOSTリクエストを送信する payload = { 'ListShow' : 'ListShow' , 'sniMtGmnId' : '' , 'dspSsuPd' : '10' , 'dspSsuPdMapOut' : '10>10件<50>50件<100>100件<200>200件<' , 'mgrMiTxtBx' : '' , 'eqMgrCd' : '13010' , 'szkbuChkbxMapOut' : '011>プライム<012>スタンダード<013>グロース<008>TOKYO PRO Market<bj1>-<be1>-<111>外国株プライム<112>外国株スタンダード<113>外国株グロース<bj2>-<be2>-<ETF>ETF<ETN>ETN<RET>不動産投資信託(REIT)<IFD>インフラファンド<999>その他<' } r = session.post('https://www2.jpx.co.jp/tseHpFront/JJK010010Action.do', data=payload) soup = BeautifulSoup(r.content, 'html.parser') r.close() print(soup.prettify())
実行結果
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html>
<head>
(中略)
<td align="center">
13010
<input name="ccJjCrpSelKekkLst_st[0].eqMgrCd" type="hidden" value="13010"/>
</td>
<td align="center">
極洋
<input name="ccJjCrpSelKekkLst_st[0].eqMgrNm" type="hidden" value="極洋"/>
</td>
<td align="center">
プライム
<input name="ccJjCrpSelKekkLst_st[0].szkbuNm" type="hidden" value="プライム"/>
</td>
<td align="center">
水産・農林業
<input name="ccJjCrpSelKekkLst_st[0].gyshDspNm" type="hidden" value="水産・農林業"/>
</td>
<td align="center" colspan="2">
3月
<input name="ccJjCrpSelKekkLst_st[0].dspYuKssnKi" type="hidden" value="3月"/>
</td>
<td align="center" style="padding-left:0px;padding-right:0px;">
</td>
<td align="center">
<input class="activeButton" name="detail_button" onclick="gotoBaseJh('13010', '1');" type="button" value="基本情報">
</input>
</td>
(以下略)
上記のように検索結果に該当するページソースが取得できれば成功です。上手くいっていないと検索ページトップのページソースが返却されます。
銘柄ページの取得
検索結果ページの取得を行った後で、同一セッションでJJK010030Action.doに対してデータをPOSTします。データの形式はあらかじめクロームの開発者ツールを使って確認しておきます。以下は開発者ツールで確認した送信データです。
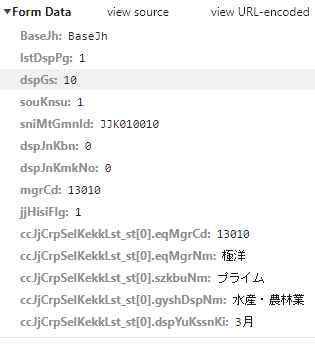
上記データの中身は銘柄ごとに異なるためページソースをパーサーで解析し、対応するinputタグのvalue属性値を入れてやる必要があります。また、名称がmgrCdであるinputタグの属性値は、基本情報ボタンをクリックした際にjavascriptが銘柄コードをvalueに設定する動きとなるため、自身で明示的に設定してやる必要があります。
import requests from bs4 import BeautifulSoup import time def getInputValue(soup, input_name) : target = soup.select_one(f'input[name="{input_name}"]') value = target['value'] return value stock_code = '42480' with requests.Session() as session : #まず、検索ページのトップにアクセスする session.get('https://www2.jpx.co.jp/tseHpFront/JJK010010Action.do') time.sleep(1) #検索のためのPOSTリクエストを送信する payload = { 'ListShow' : 'ListShow' , 'sniMtGmnId' : '' , 'dspSsuPd' : '10' , 'dspSsuPdMapOut' : '10>10件<50>50件<100>100件<200>200件<' , 'mgrMiTxtBx' : '' , 'eqMgrCd' : stock_code , 'szkbuChkbxMapOut' : '011>プライム<012>スタンダード<013>グロース<008>TOKYO PRO Market<bj1>-<be1>-<111>外国株プライム<112>外国株スタンダード<113>外国株グロース<bj2>-<be2>-<ETF>ETF<ETN>ETN<RET>不動産投資信託(REIT)<IFD>インフラファンド<999>その他<' } r = session.post('https://www2.jpx.co.jp/tseHpFront/JJK010010Action.do', data=payload) time.sleep(1) #銘柄ページ取得のためのPOSTリクエストを送信する #データの値が銘柄ごとに変化するためページソースから値を拾ってくるようにした soup = BeautifulSoup(r.content, 'html.parser') payload = { 'BaseJh' : getInputValue(soup, 'BaseJh') , 'lstDspPg' : getInputValue(soup, 'lstDspPg') , 'dspGs' : getInputValue(soup, 'dspGs') , 'souKnsu' : getInputValue(soup, 'souKnsu') , 'sniMtGmnId' : getInputValue(soup, 'sniMtGmnId') , 'dspJnKbn' : getInputValue(soup, 'dspJnKbn') , 'dspJnKmkNo' : getInputValue(soup, 'dspJnKmkNo') , 'mgrCd' : stock_code , 'jjHisiFlg' : getInputValue(soup, 'jjHisiFlg') , 'ccJjCrpSelKekkLst_st[0].eqMgrCd' : getInputValue(soup, 'ccJjCrpSelKekkLst_st[0].eqMgrCd') , 'ccJjCrpSelKekkLst_st[0].eqMgrNm' : getInputValue(soup, 'ccJjCrpSelKekkLst_st[0].eqMgrNm') , 'ccJjCrpSelKekkLst_st[0].szkbuNm' : getInputValue(soup, 'ccJjCrpSelKekkLst_st[0].szkbuNm') , 'ccJjCrpSelKekkLst_st[0].gyshDspNm' : getInputValue(soup, 'ccJjCrpSelKekkLst_st[0].gyshDspNm') , 'ccJjCrpSelKekkLst_st[0].dspYuKssnKi' : getInputValue(soup, 'ccJjCrpSelKekkLst_st[0].dspYuKssnKi') } r = session.post('https://www2.jpx.co.jp/tseHpFront/JJK010030Action.do', data=payload) time.sleep(1) soup = BeautifulSoup(r.content, 'html.parser') r.close() print(soup.prettify())
実行結果
(略)
<h4>
適時開示情報
</h4>
<span class="colorRed2 fontsizeS">
・[決算情報]
</span>
<table border="0" cellpadding="0" cellspacing="0" class="fontsizeS margin10" id="closeUpKaiJi0_open" width="840">
<tr>
<th align="left" nowrap="nowrap" width="20%">
<input class="activeButton" onclick="javascript:changeCloseUpStatus('closeUpKaiJi0');displayMore('1101', '111', '1');" type="button" value="情報を閲覧する場合はこちら"/>
</th>
</tr>
</table>
<table border="0" cellpadding="0" cellspacing="0" class="fontsizeS margin10" id="closeUpKaiJi0" style="display:none;border:none" width="840">
<tr>
<td align="left" nowrap="nowrap" style="border:none">
<input class="activeButton" id="closeUpKaiJi0_close" onclick="changeCloseUpStatus('closeUpKaiJi0');" style="display:none;" type="button" value="閉じる"/>
</td>
(略)
上記のように開示情報を格納するtableタグがソースにあれば成功です。
ページソースをパースし、XBRLのURLを取得する
あとは取得したページソースをパースして、必要情報を取得するだけです。XBRLのURLが取得でき、かつ、表題に「決算短信」というワードが含まれるもののみを選別します。
ソースはhtmlソースを解析する部分のみを抜粋しています。
import requests from bs4 import BeautifulSoup import time import urllib.parse def getInputValue(soup, input_name) : target = soup.select_one(f'input[name="{input_name}"]') value = target['value'] return value stock_code = '13010' with requests.Session() as session : (中略) xbrl_record_list = list() #まずは情報取得元となるtable要素を取得する target_table_elm_list = list() table_elms = soup.select('div.pagecontents > table') for table_elm in table_elms : table_id = table_elm.get('id') if (table_id != None) and ('KaiJi' in table_id or 'Fili' in table_id) and ('open' not in table_id) : target_table_elm_list.append(table_elm) #開示、縦覧書類の一覧を取得する for table_elm in target_table_elm_list : #欲しい情報は入れ子となっているテーブル要素内にある inner_table_elm = table_elm.select_one('table') #内部tableタグのtr要素のうちid設定があるもののみを処理する tr_elms = inner_table_elm.select('tr') for tr_elm in tr_elms : tr_id = tr_elm.get('id') if tr_id == None : continue date_str = '' title_str = '' pdf_url_str = '' xbrl_url_str = '' # #開示日、表題、pdfのurl、xbrlのurlを取得する # #1つ目のtd要素に開示日 date_str = tr_elm.select_one('td:nth-of-type(1)').get_text().strip() #2つ目のtd要素内のaタグ内に表題及びpdfのurl target_td_elm = tr_elm.select_one('td:nth-of-type(2)') a_elm = target_td_elm.select_one('a') title_str = a_elm.get_text().strip() pdf_url_str =urllib.parse.urljoin('https://www2.jpx.co.jp', a_elm.get('href').strip()) #4つ目のtd要素内のimgタグ内にxbrlのurl target_td_elm = tr_elm.select_one('td:nth-of-type(4)') img_elm = target_td_elm.select_one('img') if img_elm != None : onclick_code_str = img_elm.get('onclick').replace('\n','').strip() xbrl_path_str_in_onclick_code = onclick_code_str.split(',')[-1].strip().replace("'", '').replace(');', '') xbrl_url_str =f'https://www2.jpx.co.jp/disc{xbrl_path_str_in_onclick_code}' if xbrl_url_str != "" : xbrl_record_list.append(f'{date_str},{title_str},{pdf_url_str},{xbrl_url_str}') for record in xbrl_record_list : if '決算短信' in record.split(',')[1] : print(f"{record.split(',')[1]},{record.split(',')[3]}")
実行結果
2024年3月期 第3四半期決算短信[日本基準](連結),https://www2.jpx.co.jp/disc/13010/081220240122517667.zip 2024年3月期 第2四半期決算短信[日本基準](連結),https://www2.jpx.co.jp/disc/13010/081220231017568093.zip 2024年3月期 第1四半期決算短信[日本基準](連結),https://www2.jpx.co.jp/disc/13010/081220230714522999.zip 2023年3月期 決算短信[日本基準](連結),https://www2.jpx.co.jp/disc/13010/081220230418548831.zip 2023年3月期 第3四半期決算短信[日本基準](連結),https://www2.jpx.co.jp/disc/13010/081220230118590592.zip (略)
決算短信に関連するXBRLのURLを取得できました。
XBRLをダウンロードする
ダウンロード処理については以下で記事にしているのでこちらを参照してください。
取得したXBRLのURLに対してダウンロード処理を行うだけでいいです。
")
おわりに
今回は東証上場会社情報サービスから決算短信のXBRLをダウンロードする方法について解説しました。次回以降は決算短信のXBRLそのものについて解説していきます。
以下が続きです。
www.quwechan.com
今回はここまでです。